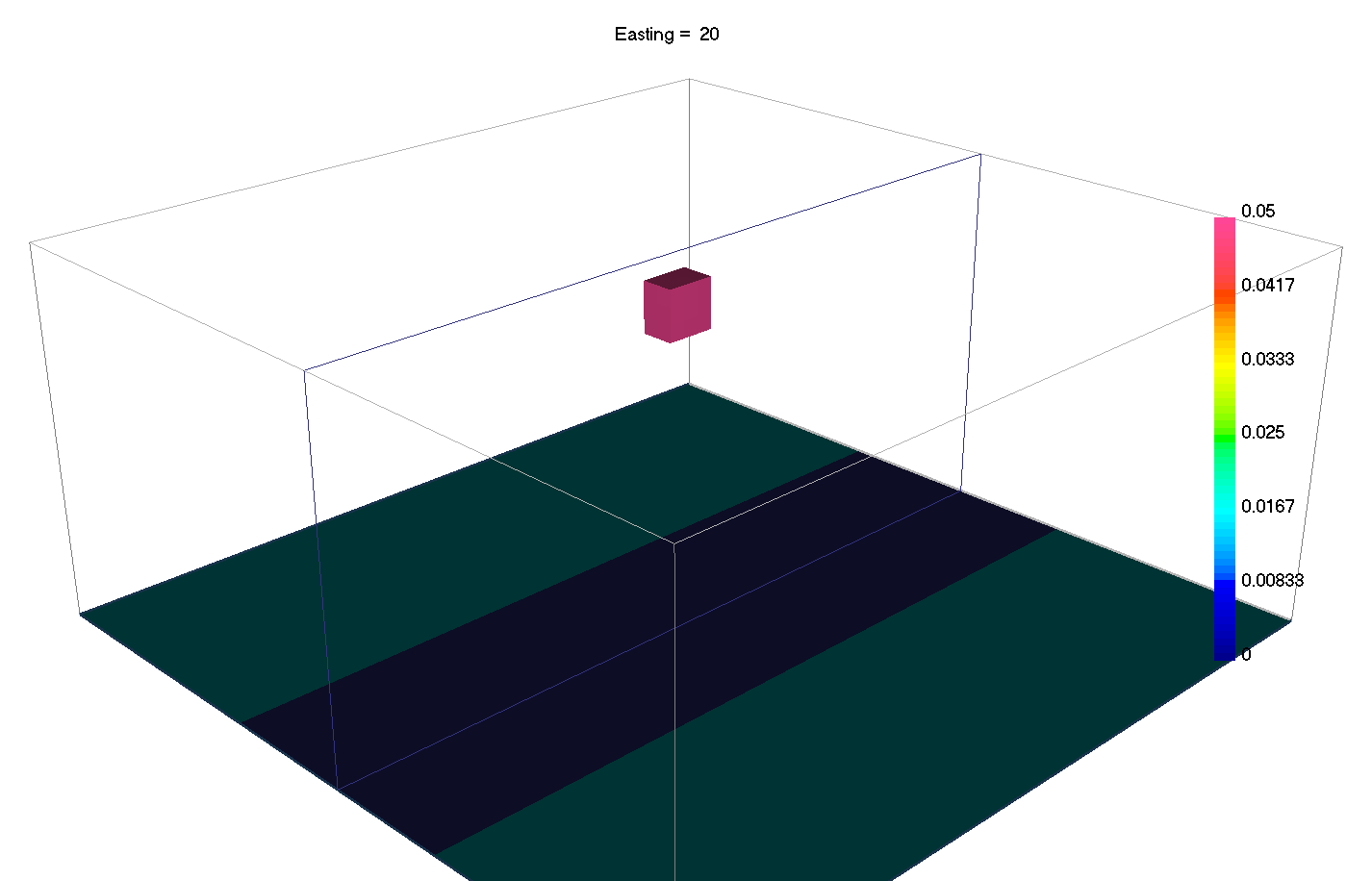
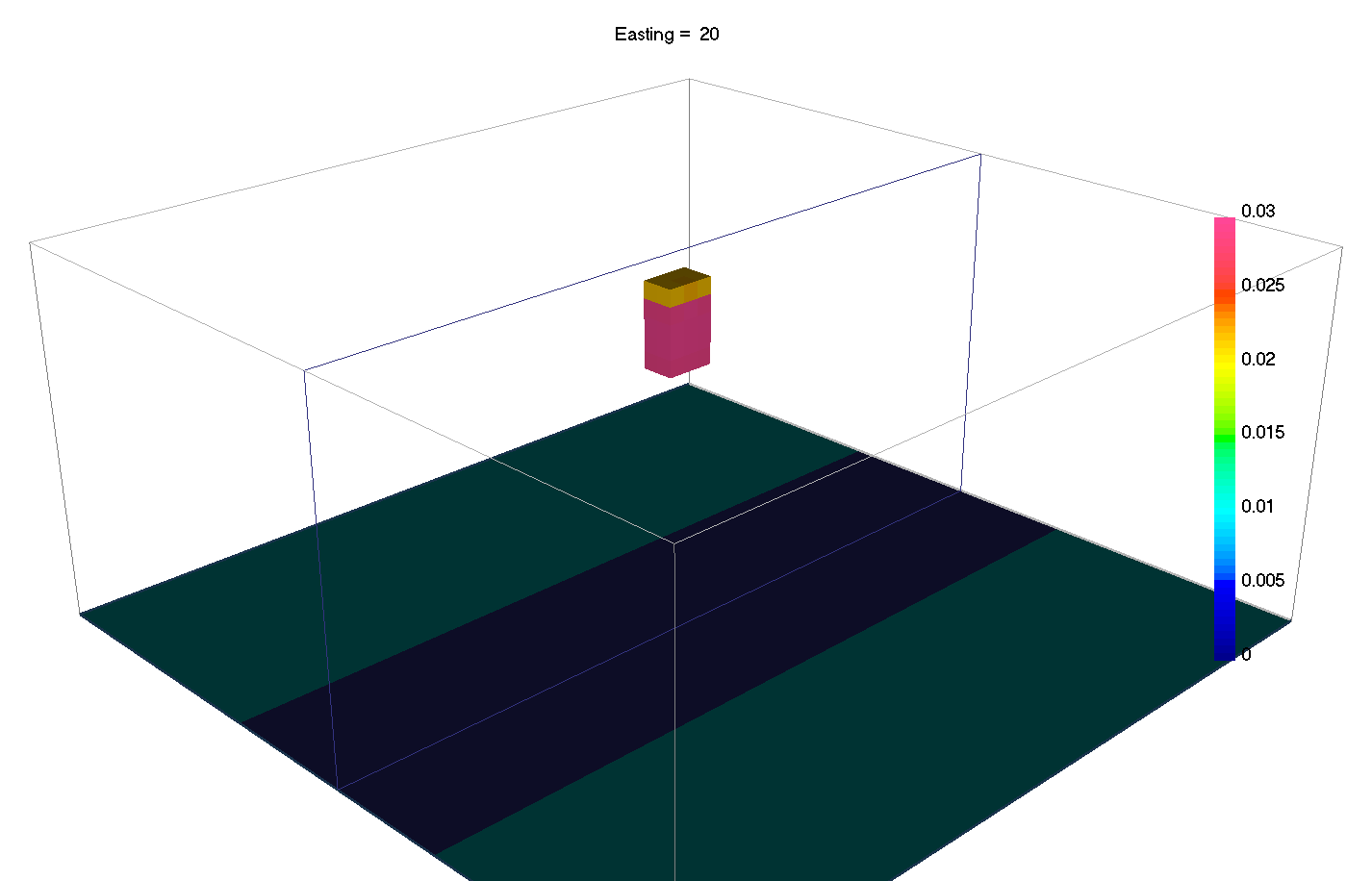
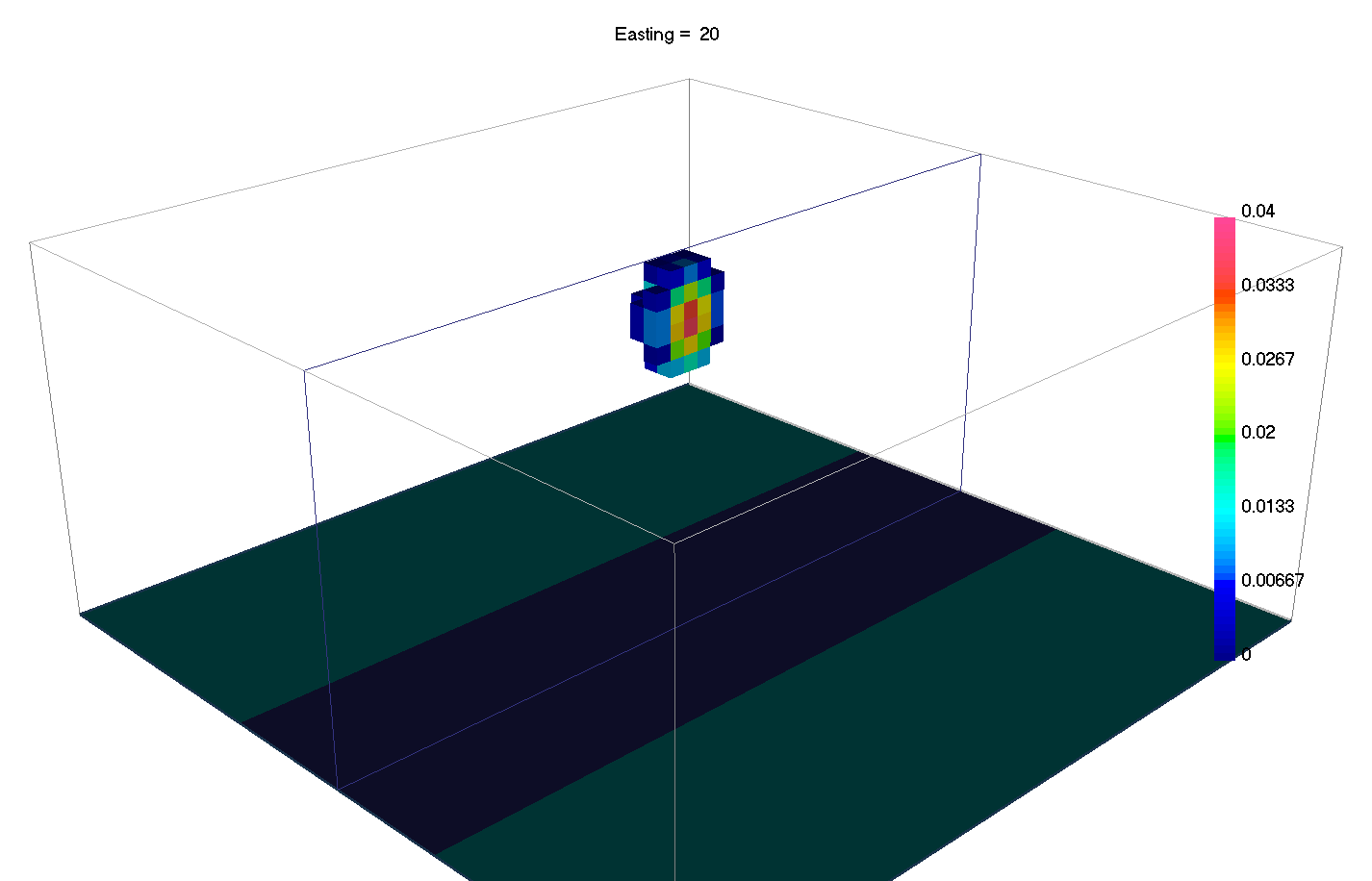
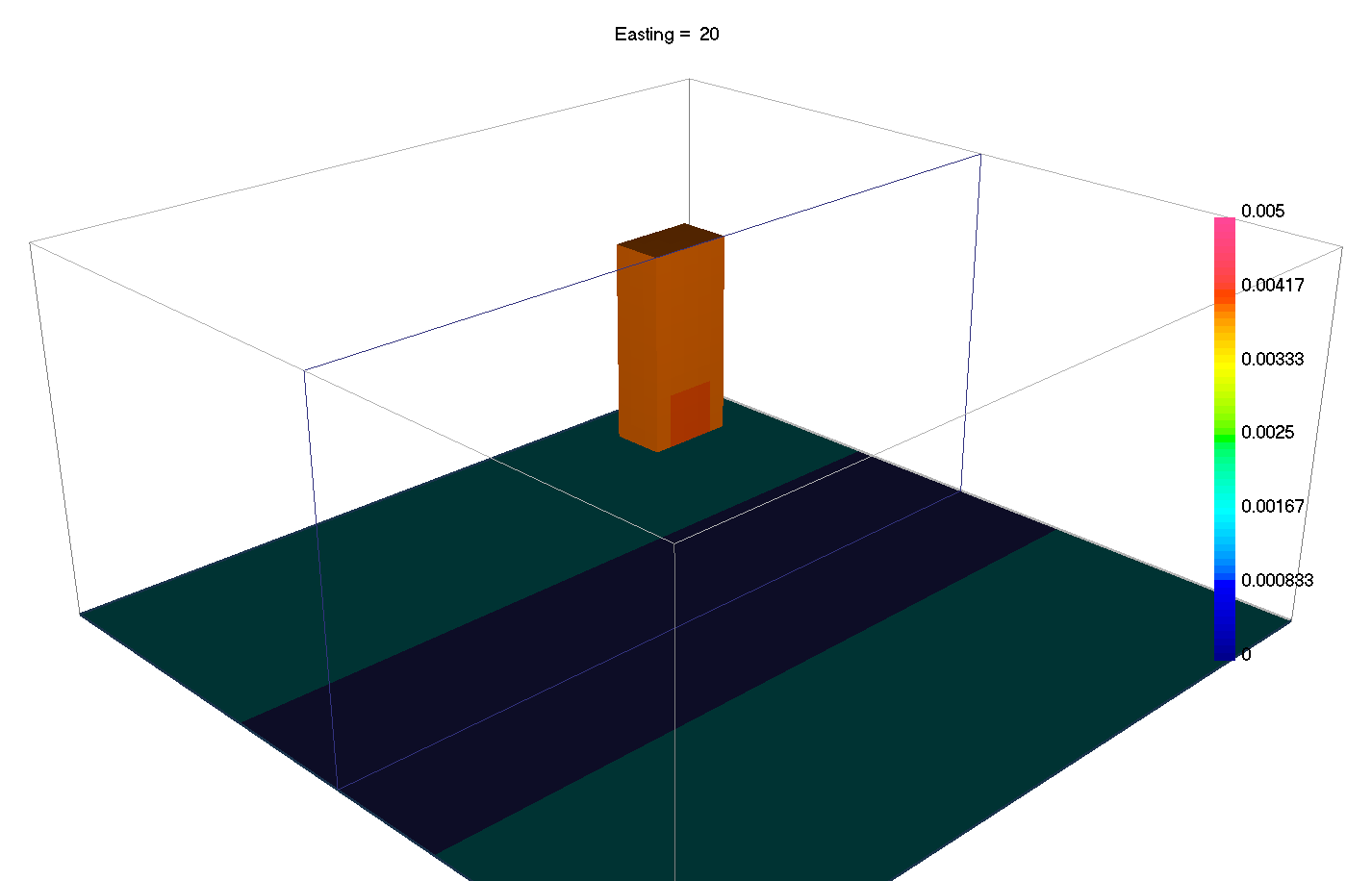
6.7. Sparse and Blocky Norms
Introduced in v6 of the gravity and magnetics codes, it is now possible to change the norms in the different part of the regularization independently. In general terms, a small \(l_p\)-norm applied on the model yields sparse solutions, while small \(l_p\)-norm on the gradients yield blocky solutions.
Most codes thus far have involved the \(l_2\)-norm which favors values that are small. Different norms tend to favor models with fewer non-zero model parameters, potentially resulting in simpler, more compact solutions. In discrete form, the general \(l_p\)-norm is written as:
which we approximate with a Scaled-IRLS methods as
where
such \(k\) denotes the iteration number and \(p\) and \(\epsilon\) are sparsity and threshold parameters respectively. A total of 6 variables can be manually adjusted by the user (\(p_s\;, p_x\;, p_y\;, p_z\;, \epsilon_s, \epsilon_{xyz}\)). The choice of \(p\) and \(\epsilon\) values is made based upon prior knowledge.